Un computer riesce per la prima volta a tradurre una lingua morta

Le moderne tecniche di traduzione automatica che si usano per tradurre in tempo reale decine di lingue parlate quasi in ogni angolo del mondo, posso aiutare a decifrare e tradurre anche le lingue morte. L’idea è stata di Jiaming Luo e Regina Barzilay del Massachusetts Institute of Technology, e Yuan Cao del laboratorio di Intelligenza Artificiale di Google. Unendo le forze hanno sviluppato una tecnica in grado di decifrare le lingue perdute.
Il lavoro, descritto in una pubblicazione scientifica su ArXiv, è stato molto complesso perché i sistemi di traduzione automatica e quelli di decifrazione dei testi antichi differiscono molto. Il concetto alla base della traduzione automatica è che le parole sono correlate l’una all’altra in modi simili, indipendentemente dalla lingua. Il computer mappa queste relazioni per una lingua specifica, passando al setaccio enormi database di testo e cercando quanto spesso ogni parola appare accanto a un’altra.

Ne segue che la parola stessa è interpretata come un vettore all’interno di uno spazio, che agisce come vincolo sul modo in cui un termine può apparire nelle traduzioni. Dato che i vettori obbediscono a regole matematiche, una frase è interpretata dal computer come un insieme di vettori che si susseguono uno dopo l’altro, disegnando una sorta di “traiettoria”. La traduzione automatica si basa sul fatto che le parole in lingue diverse occupano gli stessi vettori nei rispettivi spazi, quindi basta trovare traiettorie simili e il gioco è fatto.
Con le lingue antiche questo metodo non si può applicare per l’impossibilità di fornire database sconfinati al computer. I ricercatori hanno dovuto trovare un altro modo per decifrare le lingue morte, e sono partiti dallo stesso punto dei linguisti che hanno decifrato la scrittura micenea e quella ugaritica. Hanno sviluppato una tecnica che usa come punto fermo un fatto noto, ossia che l’evoluzione delle lingue nel tempo ha comportato l’impiego di simboli simili, con una distribuzione simile nei testi. Hanno quindi messo alla prova il computer con la traduzione del Lineare B e dell’ugaritico. Lineare B è un sistema di scrittura usato dai micenei (e ritenuto una forma arcaica del greco) decifrato per la prima volta dal linguista Miachael Ventris. L’ugaritico è una prima forma di ebraico.
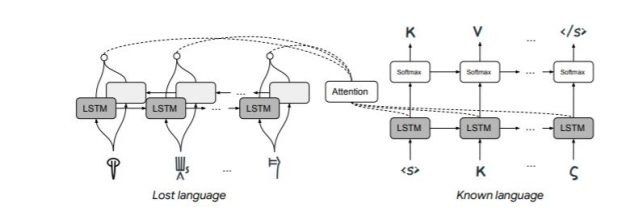
Il risultato è stata una traduzione del Lineare B con una correttezza pari al 67,3% nel suo equivalente in lingua greca. Considerato che è la prima volta che si tenta una traduzione automatica del Lineare B, è da considerarsi un grande successo.
Questo passo avanti epocale nella traduzione automatica potrebbe aprire le porte alla comprensione di moltissime lingue morte tuttora incomprese, come ad esempio la Lineare A. Forse è azzardato paragonare questo approccio informatico alla Stele di Rosetta, che fu la chiave per la comprensione dei geroglifici egiziani. Tuttavia, se lo schema dovesse confermarsi efficace non sarebbe da escludere una possibile traduzione con sistemi di “forza bruta”, ossia tentare la traduzione di ogni parola in qualsiasi lingua conosciuta dal computer, fino a dare un senso ai simboli sconosciuti.
Di sicuro ci vorranno significativi passi avanti prima che questa tecnica diventi a tutti gli effetti uno strumento per la “traduzione automatica” di qualsiasi lingua.