L’Intelligenza Artificiale di Samsung cambia il punto di vista di un video in un batter d’occhio

Partire da un banale video e ottenere scene 3D realistiche è possibile, grazie all’impiego di reti neurali sviluppate in origine per i videogiochi. Sono riusciti a farlo i ricercatori del Samsung AI Center con il supporto del Skolkovo Institute of Science and Technology.
Il video originario è stato trasformato in un mucchio di punti che rappresentano la geometria della scena. I punti, che formano una sorta di nuvola, vengono dati in pasto alla rete neurale che li trasforma in un prodotto di computer grafica. Il video qui sotto è esplicativo ed è affascinante: ciascun punto della scena originaria viene usato come descrittore neurale per codificare la geometria e l’aspetto di ciascun oggetto presente nella scena. A questo punto la rete neurale si mette al lavoro e crea nuove “viste” della scena, generando dal nulla i nuovi punti di vista nel modo più verosimile possibile.
La buona riuscita dell’esperimento è dovuta all’impiego di una tecnica molto in voga al momento, e di cui abbiamo parlato più volte in passato: GAN (Generative Adversarial Network). È una soluzione che si usa da tempo nei videogiochi e che sta trovando largo impiego in numerosi studi sulla morfologia, il fotoritocco e l’animazione e molto altro. Semplificando, sfrutta due Intelligenze Artificiali separate. Una si occupa di creare qualcosa, l’altra ne analizza i risultati, cercando di trovare errori o dettagli che in qualche modo ne mettano in discussione la credibilità. Questa sorta di “controllo incrociato” ha già dato prova molte volte di essere efficace, e a questo giro si riconferma tale.
Perché applicarla a un video? Dmitry Ulyanov di Samsung AI ha spiegato alla stampa statunitense che “l’idea è di imparare a ricreare una scena da qualsiasi punto di vista”. Al momento la tecnica messa a punto riesce a gestire lievi spostamenti in prospettiva, e lo zoom. La prospettiva è di creare letteralmente un punto di vista diverso di una scena. Si pensi, ad esempio, ai video di sorveglianza: in caso di necessità, con una versione evoluta di questa tecnica si potrebbero vedere particolari che sfuggono alla visione delle immagini originali.
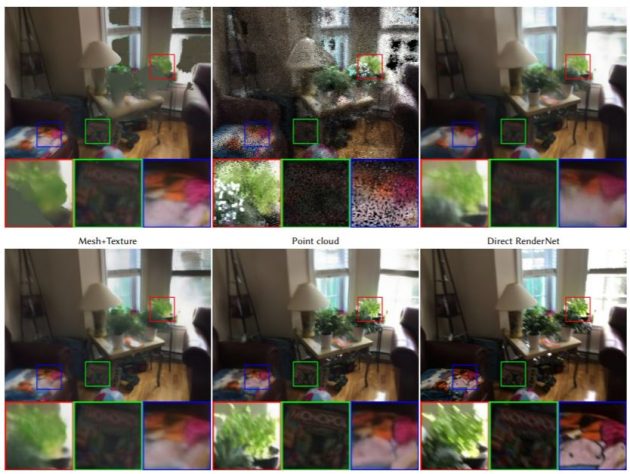





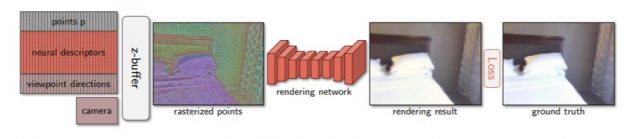






È da sottolineare che non è impossibile ottenere risultati simili con tecniche tradizionali, ma sono necessari molto tempo, competenze umane specifiche e computer molto potenti per l’elaborazione. Il sistema basato su punti neurali potrebbe “sfornare” il risultato in una frazione del tempo, e con una quantità relativamente bassa di risorse.