I nostri dati anonimi non sono poi così anonimi, dicono gli scienziati dell’Imperial College londinese

Grazie al Regolamento generale sulla protezione dei dati (GDPR) gli utenti hanno iniziato a sentirsi più tutelati, perché i dati collezionati da siti, servizi e app devono essere anonimi, e chi vìola la normativa è sottoposto a sanzioni amministrative anche pesanti. Almeno così si credeva. Fino a quando un gruppo di ricercatori dell’Imperial College di Londra ha pubblicato i risultati di uno studio in cui dimostrano come i set di dati anonimi possano essere nuovamente ricollegati ai legittimi proprietari, usando l’apprendimento automatico.
La dimostrazione è talmente convincente da essersi guadagnata anche la pubblicazione sulla rivista scientifica Nature Communications. I ricercatori affermano di avere le prove per dimostrare che, nonostante un set di dati sia stato reso anonimo con strumenti informatici e in conformità da quanto stabilito dalle normative vigenti, la privacy del proprietario non sia affatto nella proverbiale “botte di ferro”.

Partendo dall’inizio, i dati identificativi degli utenti (ad esempio nomi e indirizzi mail) vengono raccolti e resi anonimi mediante tecniche come lo “stripping” (letteralmente “fare a strisce”). Questa tecnica consiste nell’archiviare i dati, ripartendoli in pacchetti mescolati come i pezzetti un puzzle: virtualmente, senza la corretta chiave di cifratura non si può tornare alla situazione di partenza. Dopo questo “trattamento”, le informazioni non sono più soggette alle normative sulla protezione dei dati, quindi possono essere liberamente utilizzate e vendute a terzi, come ad esempio le società pubblicitarie e i broker di dati.
I ricercatori londinesi hanno preso campioni di questo “frullato” di dati senza senso e sono riusciti a retro-ingegnerizzarli usando l’apprendimento automatico, fino a identificare nuovamente gli individui a cui appartenevano. Con la stessa tecnica le aziende potrebbero creare profili personali sempre più completi di decine di migliaia di individui.
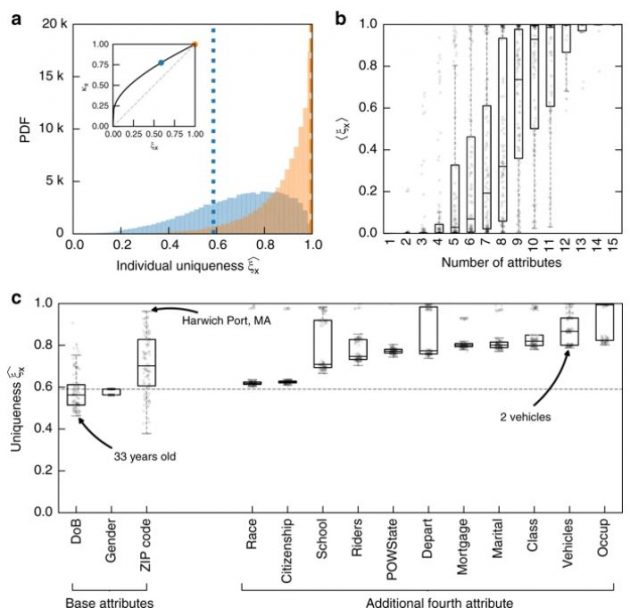
A preoccupare è che la retro-ingegnerizzazione è stata facile e precisa, anche con set di dati incompleti. Per avere un ordine di grandezza, basti sapere che nella ricerca, il 99,98% degli utenti americani è stato correttamente identificato in qualsiasi set di dati “anonimizzato” disponibile, utilizzando solo 15 caratteristiche, tra cui età, sesso e stato civile.
Il primo autore dello studio scientifico, Luc Rocher, spiega che “potrebbero esserci molte persone di sesso maschile che hanno trent’anni e vivono a New York City, molti meno sono nati il 5 gennaio, guidano un’auto sportiva rossa e vivono con due bambine e un cane”. Cosa significa? Che per risalire all’identità dei proprietari di dati i ricercatori hanno sviluppato un modello di apprendimento automatico che valuta le probabilità. In questo caso la valutazione riguarda determinate caratteristiche di un individuo che possano descrivere una sola persona, in una popolazione di miliardi. La normativa per la privacy impone di anonimizzare nome e email, non il colore dell’auto e altri dettagli secondari.
Tuttavia, è proprio usando i dati secondari che si può risalire all’identità di una persona. Più in dettaglio, basta avere la prima parte del codice postale (se residenti nel Regno Unito) o del CAP (USA), sesso e data di nascita. Se poi si hanno anche stato civile, il numero di veicoli, proprietà della casa e stato di occupazione, l’identificazione univoca di una persona è un gioco da ragazzi.
L’autore principale dello studio, Yves-Alexandre de Montjoye del Dipartimento di Informatica dell’Imperial College, spiega che “Queste sono informazioni standard che le aziende possono chiedere. Sebbene siano vincolate dalle linee guida del GDPR, sono libere di circolare una volta anonimizzate. La nostra ricerca mostra quanto facilmente – e con precisione – gli individui possano essere rintracciati una volta che ciò sia accaduto. Le aziende e i governi hanno minimizzato il rischio di ri-identificazione, sostenendo che i set di dati che vendono sono sempre incompleti. I nostri risultati contraddicono questo, e dimostrano che qualcuno potrebbe facilmente e con precisione stimare la probabilità che i dati in loro possesso appartengano alla persona che stanno cercando”.